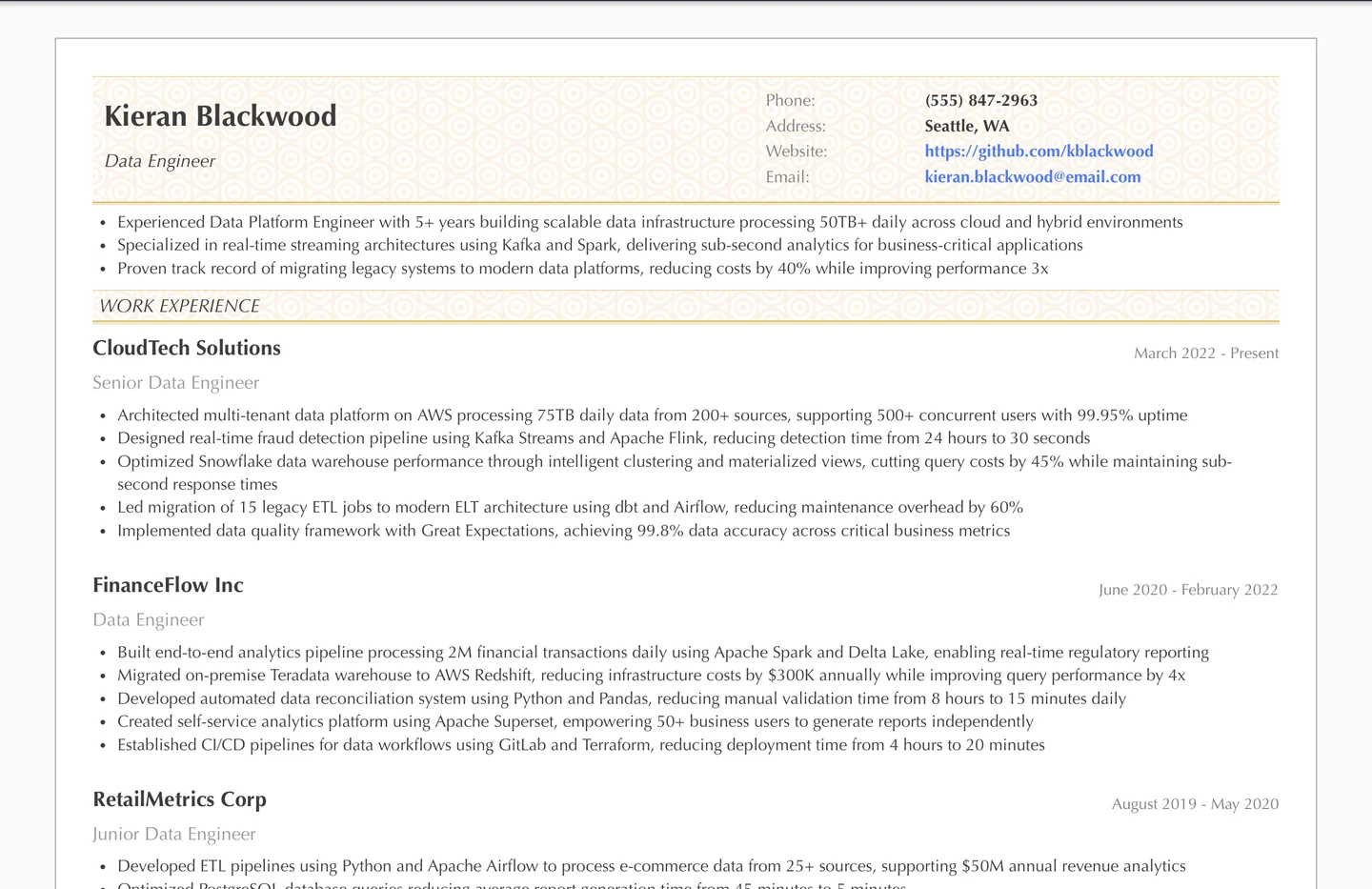
You've been deep in the data trenches for years now - wrestling with Apache Spark at 2 AM, optimizing queries that would make a DBA weep, and building pipelines that transform chaos into insights.
Maybe you started as a software engineer who got curious about where all that application data went, or perhaps you were the SQL wizard who gradually took on more infrastructure responsibilities. Either way, you've earned your stripes as a Data Engineer, and now it's time to capture all that hard-won expertise in a resume that actually does you justice.
Here's the thing about being a Data Engineer - you occupy a unique space in the tech ecosystem. You're not quite a software engineer (though you code daily), not exactly a data scientist (though you understand their needs intimately), and definitely not just a database administrator (though you've probably optimized your share of indexes). You're the architect of data highways, the guardian of data quality, and often the unsung hero who ensures everyone else in the organization can actually access and trust the data they need. Your resume needs to reflect this multifaceted expertise while speaking directly to hiring managers who understand the critical nature of your role.
In this comprehensive guide, we'll walk through every element of crafting a compelling Data Engineer resume. We'll start with choosing the right format - specifically, why the reverse-chronological approach works best for showcasing your progression from junior engineer to data infrastructure expert. Then we'll dive deep into articulating your work experience with the kind of specificity and impact metrics that make hiring managers take notice. We'll explore which technical skills to highlight (and which to leave off), tackle the unique considerations that set Data Engineer resumes apart from generic tech resumes, and show you how to present your educational background in a way that reinforces your technical credibility.
We'll also cover the often-overlooked sections that can give you an edge - from showcasing relevant awards and publications to crafting a cover letter that demonstrates both technical depth and business acumen. By the end, you'll have a clear roadmap for creating a resume that not only lists your experience but tells the story of a Data Engineer who can build robust, scalable systems that turn raw data into business value. Whether you're targeting a role at a cutting-edge startup building their first data platform or a Fortune 500 company modernizing their data infrastructure, this guide will help you present yourself as the Data Engineer they need.
Picture this - you've spent countless hours writing complex ETL pipelines, optimizing database queries, and building data warehouses that would make any architect jealous.
Now you're staring at a blank document, wondering how to translate all that technical wizardry into a resume that actually gets noticed. The format you choose can make the difference between landing that interview at your dream company or getting lost in the digital void.
As a Data Engineer, you're applying for a mid-level technical role that sits at the intersection of software engineering and data science.
Your potential employers want to see your progression through increasingly complex data challenges. The reverse-chronological format serves you perfectly here - it immediately showcases your most recent (and likely most advanced) work with data infrastructure, cloud platforms, and modern data stack tools.
Think about it - the hiring manager reviewing your resume probably has 50 others to go through. They want to quickly understand if you've worked with their tech stack, handled similar data volumes, and solved comparable problems. Starting with your latest role lets them make that assessment in seconds.
Your resume should flow like a well-designed data pipeline - each section feeding seamlessly into the next.
Start with a compelling professional summary that captures your expertise in 2-3 lines. Skip the objective statement - you're not fresh out of college anymore, and everyone knows you want the job.
Follow this with your work experience section (the meat of your resume), then your technical skills, education, and finally any relevant certifications or notable projects. This structure mirrors how technical hiring managers think - they care most about what you've built and delivered, then what tools you know, and lastly your formal credentials.
If you're applying in the USA or Canada, stick to a one-page resume unless you have 10+ years of experience.
UK and Australian employers are more forgiving with length - two pages are perfectly acceptable even for mid-level roles. In the UK, they might call it a CV, but the format remains largely the same for technical roles like Data Engineering.
Your work experience section is where the rubber meets the road - or rather, where the data meets the pipeline.
This is your chance to prove you're not just another person who completed a few online courses and knows what Apache Spark is. You need to demonstrate that you've actually built systems that process millions of records, survived production outages at 3 AM, and delivered real business value through data infrastructure.
The biggest mistake Data Engineers make? Writing job descriptions instead of accomplishments. Nobody cares that you "maintained data pipelines" - every Data Engineer does that.
What they want to know is how you improved those pipelines, what challenges you overcame, and what impact your work had on the business.
Start each bullet point with a strong action verb that reflects the technical nature of your work - architected, optimized, migrated, automated, orchestrated. Then follow with the specific technology or approach you used, and crucially, end with the measurable impact.
❌ Don't write vague descriptions:
• Worked on data pipelines using Python and SQL
• Maintained databases and performed regular updates
• Collaborated with data science team on various projects
✅ Do write specific, impactful statements:
• Architected real-time data pipeline using Apache Kafka and Spark Streaming, processing 2M events/day with 99.9% uptime
• Optimized PostgreSQL queries reducing average runtime from 45 minutes to 3 minutes, enabling hourly business reporting
• Migrated legacy on-premise data warehouse to AWS Redshift, cutting infrastructure costs by 40% while improving query performance by 3x
You work with data all day, so use it to your advantage.
Every bullet point should ideally include numbers - data volumes processed, performance improvements achieved, cost savings delivered, or uptime percentages maintained. If you reduced data processing time from 6 hours to 30 minutes, that's not just a technical achievement - that's 5.5 hours of compute cost saved and faster business insights delivered.
Your work experience should tell a story of growing technical sophistication.
Maybe you started by writing SQL queries and Python scripts, then moved to building ETL pipelines with Airflow, and now you're designing entire data platforms on cloud infrastructure. This progression shows you're not just maintaining status quo but actively growing your skills and taking on bigger challenges.
Here's where things get interesting - and slightly overwhelming.
As a Data Engineer, you probably know dozens of technologies, from programming languages to cloud platforms to orchestration tools. The temptation is to list everything you've ever touched, creating a keyword soup that supposedly will get you past resume filters. Resist this urge. Your skills section should be a carefully curated showcase of technologies where you have real, production-level expertise.
Think of your skills section as a well-organized data catalog. Group related technologies together so hiring managers can quickly assess your capabilities in key areas.
Create clear categories that reflect the main pillars of data engineering work.
A well-structured skills section might look like this:
Programming Languages: Python, Scala, SQL, Java
Big Data Technologies: Apache Spark, Hadoop, Kafka, Flink
Cloud Platforms: AWS (S3, EMR, Glue, Redshift), GCP (BigQuery, Dataflow)
Databases: PostgreSQL, MySQL, MongoDB, Cassandra, Redis
Data Orchestration: Apache Airflow, Luigi, Prefect
Data Modeling: Dimensional modeling, Data Vault, Star Schema
DevOps & Tools: Docker, Kubernetes, Git, CI/CD, Terraform
Not all skills are created equal.
That online tutorial you did on Neo4j last weekend doesn't belong next to the Spark expertise you've honed over three years. Be honest about your proficiency levels. If a job posting emphasizes real-time streaming and you list Kafka prominently, you better be ready to discuss partition strategies and exactly-once semantics in your interview.
Consider tailoring your skills section for each application. Applying for a role heavy on AWS? Make sure your AWS services are front and center. Is the company migrating from on-premise to cloud?
Highlight your experience with both environments.
While your technical skills get you in the door, don't completely ignore the human side of data engineering. You're often the bridge between data scientists hungry for clean datasets and business stakeholders who just want their dashboards to load faster.
Skills like "cross-functional collaboration," "technical documentation," and "stakeholder communication" can set you apart from the engineer who only speaks in technical jargon.
Now for the insider knowledge - the things that separate a good Data Engineer resume from one that makes hiring managers sit up and take notice. You're not applying for a generic software engineering role or a data analyst position.
Data Engineering has its own unique challenges and expectations, and your resume needs to reflect that understanding.
Unlike pure software engineers who might focus on application features, or data scientists who concentrate on models and insights, you need to demonstrate mastery of the entire data journey. Your resume should reflect experience with data ingestion (batch and streaming), transformation (ETL/ELT), storage (data lakes and warehouses), and making data accessible for consumption.
Even if you specialize in one area, showing awareness of the full pipeline proves you understand how your work fits into the bigger picture.
Here's something specific to Data Engineering - companies are increasingly divided between those building on established platforms (Snowflake, Databricks, BigQuery) versus those cobbling together open-source tools. Your resume needs to clearly indicate which camp you're in, or better yet, show experience with both approaches. If you've only worked with managed services, consider highlighting any experience with lower-level implementations.
Conversely, if you've been deep in the open-source trenches, emphasize your ability to evaluate and adopt commercial solutions.
❌ Don't just list platform names:
Experience with Databricks and Snowflake
✅ Do show depth of platform knowledge:
Designed multi-cluster Databricks architecture supporting 50+ concurrent users, implemented Delta Lake for ACID transactions
Optimized Snowflake warehouse sizing and clustering strategies, reducing compute costs by 35% while maintaining query performance
The dirty secret of Data Engineering is that the title means different things at different companies. At a startup, you might be doing everything from setting up Postgres replicas to building ML pipelines. At a large corporation, you might specialize solely in real-time streaming infrastructure.
Your resume needs to quickly clarify what type of Data Engineer you are.
Include a brief descriptor in your summary or headline that positions you correctly. Are you a "Data Platform Engineer" who builds infrastructure? An "Analytics Engineer" who focuses on transformation and modeling? A "Full-Stack Data Engineer" who handles everything? This clarity helps recruiters and hiring managers immediately understand if you're a fit for their specific needs.
Unlike many technical roles, Data Engineering has a vibrant open-source ecosystem. If you've contributed to Apache projects, created useful data processing libraries, or even written thoughtful bug reports for tools like dbt or Airflow, include this. It shows you're not just a user of tools but someone who understands them deeply enough to improve them.
Plus, it demonstrates you can work with distributed teams - a crucial skill when many data teams are remote.
The certification question is particularly thorny for Data Engineers.
While cloud certifications (AWS Certified Data Analytics, Google Cloud Professional Data Engineer) can be valuable, especially early in your career, don't let them overshadow real-world experience. If you have them, list them briefly at the bottom. If you don't, don't panic - most hiring managers care far more about what you've built than what exams you've passed.
What matters more than certifications? Demonstrable experience with production systems at scale.
A single line about handling 10TB daily data loads or maintaining sub-second query times on billion-row tables speaks volumes more than any certificate.
Come, let's visualize this - you've spent countless hours wrestling with SQL queries, debugging Python scripts, and maybe even survived the gauntlet of a Computer Science degree.
Now you're staring at your resume, wondering how to translate your educational journey into something that screams "hire me as a Data Engineer!"
Let's face it, as someone entering or advancing in the data engineering field, your education section needs to do more than just list where you went to school.
Here's the thing about being a Data Engineer - unlike some professions where education takes a backseat to experience, your academic background often serves as the foundation that proves you understand the complex technical concepts you'll be working with daily.
If you're fresh out of college or have less than 3 years of experience, your education should sit prominently near the top of your resume. However, if you've been building data pipelines for years, it can gracefully slide down below your experience section.
Data Engineering sits at the intersection of computer science, mathematics, and business intelligence.
Your education section should reflect this multidisciplinary nature. Include your formal degrees first - whether it's Computer Science, Data Science, Information Systems, Mathematics, Statistics, or even Engineering. But here's where it gets interesting - also include relevant certifications, bootcamps, and specialized courses that demonstrate your commitment to the field.
Let us show you the difference between a basic education entry and one that actually catches a hiring manager's attention:
❌ Don't write vaguely:
Bachelor of Science in Computer Science
State University, 2022
✅ Do provide context and relevance:
Bachelor of Science in Computer Science | GPA: 3.7/4.0
State University | May 2022
Relevant Coursework: Database Systems, Big Data Analytics, Distributed Computing,
Machine Learning, Data Structures & Algorithms
Capstone Project: Built ETL pipeline processing 500GB daily transaction data using Apache Spark
As a Data Engineer, you're expected to have a solid grasp of both theoretical concepts and practical applications. Your education section is the perfect place to showcase academic projects that mirror real-world data engineering challenges. Did you build a data warehouse for your database class? Create a streaming data pipeline for your capstone?
These academic achievements directly translate to the skills employers seek.
The data engineering landscape evolves rapidly, and certifications demonstrate your commitment to staying current. Include relevant certifications like AWS Certified Data Analytics, Google Cloud Professional Data Engineer, or Databricks Certified Associate Developer.
These belong in your education section, especially if you're early in your career.
❌ Don't just list certifications without context:
AWS Certified Solutions Architect
Google Cloud Certified
✅ Do provide completion dates and relevance:
AWS Certified Data Analytics - Specialty | March 2023
Google Cloud Professional Data Engineer | January 2023
Coursera - Data Engineering with Google Cloud Professional Certificate | December 2022
If you're applying in the USA or Canada, including your GPA is standard practice if it's 3.5 or higher. In the UK and Australia, classification honors (First Class, 2:1, etc. ) are more common.
For international degrees, consider including a brief equivalency note to help recruiters understand your qualifications in their local context.
You might be thinking - "I'm a Data Engineer, not a research scientist. Do awards and publications even matter?" Well, imagine you're building a data pipeline that processes millions of records daily. Now imagine you published a paper on optimizing such pipelines or won a hackathon by creating an innovative data solution.
Suddenly, you're not just another Data Engineer - you're someone who pushes boundaries and shares knowledge with the community.
In the data engineering world, awards serve as third-party validation of your skills. They show you can deliver under pressure, think creatively, and often work collaboratively - all crucial traits for a Data Engineer.
Whether it's winning a Kaggle competition, receiving recognition at a company hackathon, or earning academic honors, these achievements differentiate you from the sea of candidates who merely list technical skills.
Not all awards are created equal in the eyes of data engineering recruiters. Focus on achievements that demonstrate technical prowess, innovation, or leadership in data-related initiatives.
Here's how to present them effectively:
❌ Don't be vague about your achievements:
Won hackathon - 2023
Published paper on databases
✅ Do provide specific, impactful details:
1st Place, TechCorp Annual Hackathon | November 2023
- Designed real-time anomaly detection system processing 1M events/second
- Reduced false positive rate by 67% using ensemble learning approach
"Optimizing Data Lake Query Performance Using Partition Pruning" | IEEE BigData 2023
- Co-authored paper demonstrating 3x query speed improvement
- Implemented solution now used in production serving 10,000+ daily queries
While Data Engineers aren't typically expected to have extensive publication records, any technical writing demonstrates valuable skills. Blog posts on Medium about your data engineering solutions, contributions to open-source documentation, or papers presented at conferences all show you can communicate complex technical concepts - a skill desperately needed when you're explaining why the ETL job failed at 3 AM to non-technical stakeholders.
If you have particularly impressive awards or publications directly related to data engineering, consider creating a dedicated section. Otherwise, weave them into your education or experience sections where they provide the most context.
For instance, a hackathon win during your time at Company X could enhance that work experience entry.
Don't overlook industry-specific recognition.
Being named a Google Developer Expert in Cloud, becoming an AWS Community Builder, or contributing significantly to Apache Spark could carry more weight than traditional academic awards. These demonstrate not just technical skill but also community engagement - something increasingly valued in the collaborative world of data engineering.
Picture this scenario - you've nailed the technical interviews, impressed them with your system design skills, and demonstrated you can optimize queries with your eyes closed. Now they want references.
As a Data Engineer, your references carry unique weight because they can vouch not just for your technical abilities, but also for something equally crucial - your ability to work with messy, real-world data and deliver solutions that actually work in production.
Data Engineering is a field where trust is paramount. You're often working with sensitive data, building critical infrastructure, and making architectural decisions that will impact the organization for years. Your references serve as testimonials that you can handle this responsibility.
They confirm that yes, you really did build that pipeline that processes billions of records, and more importantly, it actually stayed running after you left.
Not all references are created equal for a Data Engineer position. Your ideal reference portfolio should include people who can speak to different aspects of your role.
Consider including a technical lead who can vouch for your engineering skills, a product manager or business analyst who can confirm your ability to translate business requirements into technical solutions, and perhaps a peer who can attest to your collaborative skills and mentorship abilities.
❌ Don't list references without context:
References:
John Smith - Manager - 555-0123
Jane Doe - Colleague - 555-0456
Bob Johnson - Director - 555-0789
✅ Do provide relevant context and prepare your references:
References available upon request
Prepared references include:
• Sarah Chen, Senior Engineering Manager at DataCorp (2021-2023)
- Can speak to: Led migration of 50TB data warehouse to cloud architecture
• Michael Rodriguez, VP of Analytics at TechStartup (2019-2021)
- Can speak to: Designed real-time analytics pipeline serving 100M daily users
• Dr. Amanda Foster, Database Systems Professor at State University
- Can speak to: Research project on distributed query optimization
In the data engineering world, real estate on your resume is precious - every line could be used to showcase another technology you've mastered or project you've completed. Unless specifically requested, the phrase "References available upon request" is generally sufficient. This is especially true in the USA and Canada.
However, some European positions may expect references listed upfront, so research the local norms.
Here's something many Data Engineers overlook - your references need preparation too. Before listing someone, have a conversation about the specific role you're applying for. Share the job description and remind them of specific projects you worked on together.
If you built a revolutionary data deduplication system that saved the company millions, make sure your reference remembers the details and impact.
In our digital age, LinkedIn recommendations can serve as pre-references, especially for Data Engineers. A well-written recommendation from a respected professional in the data space can carry significant weight. Consider cultivating these throughout your career, not just when job hunting.
They provide social proof that's immediately accessible to recruiters and hiring managers.
What if your best data engineering work was at a company with strict confidentiality agreements? Or what if you're making your first transition into data engineering from a related field? In these cases, focus on references who can speak to transferable skills - your analytical thinking, problem-solving abilities, and capacity to learn new technologies quickly.
A reference confirming you mastered Apache Spark in three weeks for a critical project can be more powerful than years of experience with less challenging work.
If you're applying internationally, be mindful of time zones when listing references.
Nothing frustrates a hiring manager more than trying to reach a reference at 3 AM their time. Include the reference's location or time zone, and consider having at least one reference in a compatible time zone with your target job location.
Also, be aware that reference checking practices vary significantly between countries - what's standard in Silicon Valley might be unusual in Singapore.
Let's be honest - as a Data Engineer, you'd probably rather spend your time optimizing a particularly stubborn SQL query than writing a cover letter.
You might even be tempted to skip it entirely, thinking your technical skills speak for themselves. But here's the reality: while your resume shows you can build robust data pipelines, your cover letter shows you can communicate why those pipelines matter to the business. And in a role where you'll often bridge the gap between technical and non-technical teams, that communication ability is gold.
Unlike software developers who might get away with letting their GitHub do the talking, Data Engineers operate in a unique space.
You're not just writing code - you're architecting the very foundation that enables data-driven decisions across an entire organization. Your cover letter needs to convey that you understand this responsibility and can articulate technical concepts to diverse audiences.
Think of your cover letter like designing a data pipeline - it needs a clear flow from input to output. Start with the problem (why you're interested in this specific role), process it through your experience (how your skills align), and deliver valuable output (what you'll bring to the team).
Here's how to structure it effectively:
❌ Don't write generic, technical jargon-filled paragraphs:
Dear Hiring Manager,
I am applying for the Data Engineer position. I have experience with Python, SQL,
and AWS. I have built many ETL pipelines and worked with big data technologies.
I think I would be a good fit for your company.
✅ Do tell a compelling story that connects your experience to their needs:
Dear Data Engineering Team at TechCorp,
When I read that you're scaling from processing 10TB to 100TB of daily data, I immediately
thought of the similar challenge I tackled at CurrentCompany. By redesigning our data
pipeline architecture using Apache Spark and implementing intelligent partitioning strategies,
I reduced processing time by 70% while cutting infrastructure costs by $200K annually.
Your job posting mentions the need for real-time analytics capabilities. In my current role,
I architected a streaming solution using Kafka and Flink that processes 2 million events per
minute with sub-second latency, enabling our product team to make instant decisions based on
user behavior...
Here's what separates great Data Engineers from good ones - the ability to connect technical solutions to business outcomes. Your cover letter should demonstrate this skill. Don't just mention that you implemented a data warehouse; explain how it enabled marketing to increase campaign ROI by 40%.
Don't just say you know Spark; describe how you used it to reduce report generation time from hours to minutes.
Maybe you're transitioning from a software engineering role, or perhaps you're a recent graduate with more academic than industry experience. Your cover letter is the perfect place to address these situations proactively.
Explain how your software engineering background gives you a unique perspective on building maintainable data systems, or how your research project on distributed systems directly applies to modern data engineering challenges.
In the USA and Canada, cover letters are typically expected and should be concise - one page maximum. UK employers often prefer a more formal tone but similar length. Australian companies tend to appreciate a bit more personality while maintaining professionalism.
Regardless of region, avoid rehashing your resume; instead, use the cover letter to provide context and demonstrate cultural fit.
For Data Engineer positions, consider including a brief technical insight that shows your expertise. Maybe you noticed they use a specific technology stack and you can share a relevant optimization technique. Or perhaps you've solved a similar challenge they mention in their engineering blog.
This shows you've done your homework and can contribute from day one.
After diving deep into the art and science of crafting the perfect Data Engineer resume, let's distill everything into actionable takeaways you can implement immediately:
Ready to transform your data engineering experience into a resume that opens doors? Resumonk makes it easy to create a professional, impactful resume that captures your unique journey as a Data Engineer. Our AI-powered platform understands the nuances of technical roles and helps you articulate your achievements in ways that resonate with hiring managers. With beautifully designed templates optimized for readability and smart suggestions tailored to data engineering roles, you can focus on showcasing your expertise while we handle the formatting and structure.
Start building your standout Data Engineer resume today!
Join thousands of data professionals who've successfully landed their dream roles using Resumonk. Our intuitive platform guides you through each section, ensuring you don't miss any crucial details that could make the difference between a callback and silence.
Get started with Resumonk now and let your data engineering expertise shine through in every line.
You've been deep in the data trenches for years now - wrestling with Apache Spark at 2 AM, optimizing queries that would make a DBA weep, and building pipelines that transform chaos into insights.
Maybe you started as a software engineer who got curious about where all that application data went, or perhaps you were the SQL wizard who gradually took on more infrastructure responsibilities. Either way, you've earned your stripes as a Data Engineer, and now it's time to capture all that hard-won expertise in a resume that actually does you justice.
Here's the thing about being a Data Engineer - you occupy a unique space in the tech ecosystem. You're not quite a software engineer (though you code daily), not exactly a data scientist (though you understand their needs intimately), and definitely not just a database administrator (though you've probably optimized your share of indexes). You're the architect of data highways, the guardian of data quality, and often the unsung hero who ensures everyone else in the organization can actually access and trust the data they need. Your resume needs to reflect this multifaceted expertise while speaking directly to hiring managers who understand the critical nature of your role.
In this comprehensive guide, we'll walk through every element of crafting a compelling Data Engineer resume. We'll start with choosing the right format - specifically, why the reverse-chronological approach works best for showcasing your progression from junior engineer to data infrastructure expert. Then we'll dive deep into articulating your work experience with the kind of specificity and impact metrics that make hiring managers take notice. We'll explore which technical skills to highlight (and which to leave off), tackle the unique considerations that set Data Engineer resumes apart from generic tech resumes, and show you how to present your educational background in a way that reinforces your technical credibility.
We'll also cover the often-overlooked sections that can give you an edge - from showcasing relevant awards and publications to crafting a cover letter that demonstrates both technical depth and business acumen. By the end, you'll have a clear roadmap for creating a resume that not only lists your experience but tells the story of a Data Engineer who can build robust, scalable systems that turn raw data into business value. Whether you're targeting a role at a cutting-edge startup building their first data platform or a Fortune 500 company modernizing their data infrastructure, this guide will help you present yourself as the Data Engineer they need.
Picture this - you've spent countless hours writing complex ETL pipelines, optimizing database queries, and building data warehouses that would make any architect jealous.
Now you're staring at a blank document, wondering how to translate all that technical wizardry into a resume that actually gets noticed. The format you choose can make the difference between landing that interview at your dream company or getting lost in the digital void.
As a Data Engineer, you're applying for a mid-level technical role that sits at the intersection of software engineering and data science.
Your potential employers want to see your progression through increasingly complex data challenges. The reverse-chronological format serves you perfectly here - it immediately showcases your most recent (and likely most advanced) work with data infrastructure, cloud platforms, and modern data stack tools.
Think about it - the hiring manager reviewing your resume probably has 50 others to go through. They want to quickly understand if you've worked with their tech stack, handled similar data volumes, and solved comparable problems. Starting with your latest role lets them make that assessment in seconds.
Your resume should flow like a well-designed data pipeline - each section feeding seamlessly into the next.
Start with a compelling professional summary that captures your expertise in 2-3 lines. Skip the objective statement - you're not fresh out of college anymore, and everyone knows you want the job.
Follow this with your work experience section (the meat of your resume), then your technical skills, education, and finally any relevant certifications or notable projects. This structure mirrors how technical hiring managers think - they care most about what you've built and delivered, then what tools you know, and lastly your formal credentials.
If you're applying in the USA or Canada, stick to a one-page resume unless you have 10+ years of experience.
UK and Australian employers are more forgiving with length - two pages are perfectly acceptable even for mid-level roles. In the UK, they might call it a CV, but the format remains largely the same for technical roles like Data Engineering.
Your work experience section is where the rubber meets the road - or rather, where the data meets the pipeline.
This is your chance to prove you're not just another person who completed a few online courses and knows what Apache Spark is. You need to demonstrate that you've actually built systems that process millions of records, survived production outages at 3 AM, and delivered real business value through data infrastructure.
The biggest mistake Data Engineers make? Writing job descriptions instead of accomplishments. Nobody cares that you "maintained data pipelines" - every Data Engineer does that.
What they want to know is how you improved those pipelines, what challenges you overcame, and what impact your work had on the business.
Start each bullet point with a strong action verb that reflects the technical nature of your work - architected, optimized, migrated, automated, orchestrated. Then follow with the specific technology or approach you used, and crucially, end with the measurable impact.
❌ Don't write vague descriptions:
• Worked on data pipelines using Python and SQL
• Maintained databases and performed regular updates
• Collaborated with data science team on various projects
✅ Do write specific, impactful statements:
• Architected real-time data pipeline using Apache Kafka and Spark Streaming, processing 2M events/day with 99.9% uptime
• Optimized PostgreSQL queries reducing average runtime from 45 minutes to 3 minutes, enabling hourly business reporting
• Migrated legacy on-premise data warehouse to AWS Redshift, cutting infrastructure costs by 40% while improving query performance by 3x
You work with data all day, so use it to your advantage.
Every bullet point should ideally include numbers - data volumes processed, performance improvements achieved, cost savings delivered, or uptime percentages maintained. If you reduced data processing time from 6 hours to 30 minutes, that's not just a technical achievement - that's 5.5 hours of compute cost saved and faster business insights delivered.
Your work experience should tell a story of growing technical sophistication.
Maybe you started by writing SQL queries and Python scripts, then moved to building ETL pipelines with Airflow, and now you're designing entire data platforms on cloud infrastructure. This progression shows you're not just maintaining status quo but actively growing your skills and taking on bigger challenges.
Here's where things get interesting - and slightly overwhelming.
As a Data Engineer, you probably know dozens of technologies, from programming languages to cloud platforms to orchestration tools. The temptation is to list everything you've ever touched, creating a keyword soup that supposedly will get you past resume filters. Resist this urge. Your skills section should be a carefully curated showcase of technologies where you have real, production-level expertise.
Think of your skills section as a well-organized data catalog. Group related technologies together so hiring managers can quickly assess your capabilities in key areas.
Create clear categories that reflect the main pillars of data engineering work.
A well-structured skills section might look like this:
Programming Languages: Python, Scala, SQL, Java
Big Data Technologies: Apache Spark, Hadoop, Kafka, Flink
Cloud Platforms: AWS (S3, EMR, Glue, Redshift), GCP (BigQuery, Dataflow)
Databases: PostgreSQL, MySQL, MongoDB, Cassandra, Redis
Data Orchestration: Apache Airflow, Luigi, Prefect
Data Modeling: Dimensional modeling, Data Vault, Star Schema
DevOps & Tools: Docker, Kubernetes, Git, CI/CD, Terraform
Not all skills are created equal.
That online tutorial you did on Neo4j last weekend doesn't belong next to the Spark expertise you've honed over three years. Be honest about your proficiency levels. If a job posting emphasizes real-time streaming and you list Kafka prominently, you better be ready to discuss partition strategies and exactly-once semantics in your interview.
Consider tailoring your skills section for each application. Applying for a role heavy on AWS? Make sure your AWS services are front and center. Is the company migrating from on-premise to cloud?
Highlight your experience with both environments.
While your technical skills get you in the door, don't completely ignore the human side of data engineering. You're often the bridge between data scientists hungry for clean datasets and business stakeholders who just want their dashboards to load faster.
Skills like "cross-functional collaboration," "technical documentation," and "stakeholder communication" can set you apart from the engineer who only speaks in technical jargon.
Now for the insider knowledge - the things that separate a good Data Engineer resume from one that makes hiring managers sit up and take notice. You're not applying for a generic software engineering role or a data analyst position.
Data Engineering has its own unique challenges and expectations, and your resume needs to reflect that understanding.
Unlike pure software engineers who might focus on application features, or data scientists who concentrate on models and insights, you need to demonstrate mastery of the entire data journey. Your resume should reflect experience with data ingestion (batch and streaming), transformation (ETL/ELT), storage (data lakes and warehouses), and making data accessible for consumption.
Even if you specialize in one area, showing awareness of the full pipeline proves you understand how your work fits into the bigger picture.
Here's something specific to Data Engineering - companies are increasingly divided between those building on established platforms (Snowflake, Databricks, BigQuery) versus those cobbling together open-source tools. Your resume needs to clearly indicate which camp you're in, or better yet, show experience with both approaches. If you've only worked with managed services, consider highlighting any experience with lower-level implementations.
Conversely, if you've been deep in the open-source trenches, emphasize your ability to evaluate and adopt commercial solutions.
❌ Don't just list platform names:
Experience with Databricks and Snowflake
✅ Do show depth of platform knowledge:
Designed multi-cluster Databricks architecture supporting 50+ concurrent users, implemented Delta Lake for ACID transactions
Optimized Snowflake warehouse sizing and clustering strategies, reducing compute costs by 35% while maintaining query performance
The dirty secret of Data Engineering is that the title means different things at different companies. At a startup, you might be doing everything from setting up Postgres replicas to building ML pipelines. At a large corporation, you might specialize solely in real-time streaming infrastructure.
Your resume needs to quickly clarify what type of Data Engineer you are.
Include a brief descriptor in your summary or headline that positions you correctly. Are you a "Data Platform Engineer" who builds infrastructure? An "Analytics Engineer" who focuses on transformation and modeling? A "Full-Stack Data Engineer" who handles everything? This clarity helps recruiters and hiring managers immediately understand if you're a fit for their specific needs.
Unlike many technical roles, Data Engineering has a vibrant open-source ecosystem. If you've contributed to Apache projects, created useful data processing libraries, or even written thoughtful bug reports for tools like dbt or Airflow, include this. It shows you're not just a user of tools but someone who understands them deeply enough to improve them.
Plus, it demonstrates you can work with distributed teams - a crucial skill when many data teams are remote.
The certification question is particularly thorny for Data Engineers.
While cloud certifications (AWS Certified Data Analytics, Google Cloud Professional Data Engineer) can be valuable, especially early in your career, don't let them overshadow real-world experience. If you have them, list them briefly at the bottom. If you don't, don't panic - most hiring managers care far more about what you've built than what exams you've passed.
What matters more than certifications? Demonstrable experience with production systems at scale.
A single line about handling 10TB daily data loads or maintaining sub-second query times on billion-row tables speaks volumes more than any certificate.
Come, let's visualize this - you've spent countless hours wrestling with SQL queries, debugging Python scripts, and maybe even survived the gauntlet of a Computer Science degree.
Now you're staring at your resume, wondering how to translate your educational journey into something that screams "hire me as a Data Engineer!"
Let's face it, as someone entering or advancing in the data engineering field, your education section needs to do more than just list where you went to school.
Here's the thing about being a Data Engineer - unlike some professions where education takes a backseat to experience, your academic background often serves as the foundation that proves you understand the complex technical concepts you'll be working with daily.
If you're fresh out of college or have less than 3 years of experience, your education should sit prominently near the top of your resume. However, if you've been building data pipelines for years, it can gracefully slide down below your experience section.
Data Engineering sits at the intersection of computer science, mathematics, and business intelligence.
Your education section should reflect this multidisciplinary nature. Include your formal degrees first - whether it's Computer Science, Data Science, Information Systems, Mathematics, Statistics, or even Engineering. But here's where it gets interesting - also include relevant certifications, bootcamps, and specialized courses that demonstrate your commitment to the field.
Let us show you the difference between a basic education entry and one that actually catches a hiring manager's attention:
❌ Don't write vaguely:
Bachelor of Science in Computer Science
State University, 2022
✅ Do provide context and relevance:
Bachelor of Science in Computer Science | GPA: 3.7/4.0
State University | May 2022
Relevant Coursework: Database Systems, Big Data Analytics, Distributed Computing,
Machine Learning, Data Structures & Algorithms
Capstone Project: Built ETL pipeline processing 500GB daily transaction data using Apache Spark
As a Data Engineer, you're expected to have a solid grasp of both theoretical concepts and practical applications. Your education section is the perfect place to showcase academic projects that mirror real-world data engineering challenges. Did you build a data warehouse for your database class? Create a streaming data pipeline for your capstone?
These academic achievements directly translate to the skills employers seek.
The data engineering landscape evolves rapidly, and certifications demonstrate your commitment to staying current. Include relevant certifications like AWS Certified Data Analytics, Google Cloud Professional Data Engineer, or Databricks Certified Associate Developer.
These belong in your education section, especially if you're early in your career.
❌ Don't just list certifications without context:
AWS Certified Solutions Architect
Google Cloud Certified
✅ Do provide completion dates and relevance:
AWS Certified Data Analytics - Specialty | March 2023
Google Cloud Professional Data Engineer | January 2023
Coursera - Data Engineering with Google Cloud Professional Certificate | December 2022
If you're applying in the USA or Canada, including your GPA is standard practice if it's 3.5 or higher. In the UK and Australia, classification honors (First Class, 2:1, etc. ) are more common.
For international degrees, consider including a brief equivalency note to help recruiters understand your qualifications in their local context.
You might be thinking - "I'm a Data Engineer, not a research scientist. Do awards and publications even matter?" Well, imagine you're building a data pipeline that processes millions of records daily. Now imagine you published a paper on optimizing such pipelines or won a hackathon by creating an innovative data solution.
Suddenly, you're not just another Data Engineer - you're someone who pushes boundaries and shares knowledge with the community.
In the data engineering world, awards serve as third-party validation of your skills. They show you can deliver under pressure, think creatively, and often work collaboratively - all crucial traits for a Data Engineer.
Whether it's winning a Kaggle competition, receiving recognition at a company hackathon, or earning academic honors, these achievements differentiate you from the sea of candidates who merely list technical skills.
Not all awards are created equal in the eyes of data engineering recruiters. Focus on achievements that demonstrate technical prowess, innovation, or leadership in data-related initiatives.
Here's how to present them effectively:
❌ Don't be vague about your achievements:
Won hackathon - 2023
Published paper on databases
✅ Do provide specific, impactful details:
1st Place, TechCorp Annual Hackathon | November 2023
- Designed real-time anomaly detection system processing 1M events/second
- Reduced false positive rate by 67% using ensemble learning approach
"Optimizing Data Lake Query Performance Using Partition Pruning" | IEEE BigData 2023
- Co-authored paper demonstrating 3x query speed improvement
- Implemented solution now used in production serving 10,000+ daily queries
While Data Engineers aren't typically expected to have extensive publication records, any technical writing demonstrates valuable skills. Blog posts on Medium about your data engineering solutions, contributions to open-source documentation, or papers presented at conferences all show you can communicate complex technical concepts - a skill desperately needed when you're explaining why the ETL job failed at 3 AM to non-technical stakeholders.
If you have particularly impressive awards or publications directly related to data engineering, consider creating a dedicated section. Otherwise, weave them into your education or experience sections where they provide the most context.
For instance, a hackathon win during your time at Company X could enhance that work experience entry.
Don't overlook industry-specific recognition.
Being named a Google Developer Expert in Cloud, becoming an AWS Community Builder, or contributing significantly to Apache Spark could carry more weight than traditional academic awards. These demonstrate not just technical skill but also community engagement - something increasingly valued in the collaborative world of data engineering.
Picture this scenario - you've nailed the technical interviews, impressed them with your system design skills, and demonstrated you can optimize queries with your eyes closed. Now they want references.
As a Data Engineer, your references carry unique weight because they can vouch not just for your technical abilities, but also for something equally crucial - your ability to work with messy, real-world data and deliver solutions that actually work in production.
Data Engineering is a field where trust is paramount. You're often working with sensitive data, building critical infrastructure, and making architectural decisions that will impact the organization for years. Your references serve as testimonials that you can handle this responsibility.
They confirm that yes, you really did build that pipeline that processes billions of records, and more importantly, it actually stayed running after you left.
Not all references are created equal for a Data Engineer position. Your ideal reference portfolio should include people who can speak to different aspects of your role.
Consider including a technical lead who can vouch for your engineering skills, a product manager or business analyst who can confirm your ability to translate business requirements into technical solutions, and perhaps a peer who can attest to your collaborative skills and mentorship abilities.
❌ Don't list references without context:
References:
John Smith - Manager - 555-0123
Jane Doe - Colleague - 555-0456
Bob Johnson - Director - 555-0789
✅ Do provide relevant context and prepare your references:
References available upon request
Prepared references include:
• Sarah Chen, Senior Engineering Manager at DataCorp (2021-2023)
- Can speak to: Led migration of 50TB data warehouse to cloud architecture
• Michael Rodriguez, VP of Analytics at TechStartup (2019-2021)
- Can speak to: Designed real-time analytics pipeline serving 100M daily users
• Dr. Amanda Foster, Database Systems Professor at State University
- Can speak to: Research project on distributed query optimization
In the data engineering world, real estate on your resume is precious - every line could be used to showcase another technology you've mastered or project you've completed. Unless specifically requested, the phrase "References available upon request" is generally sufficient. This is especially true in the USA and Canada.
However, some European positions may expect references listed upfront, so research the local norms.
Here's something many Data Engineers overlook - your references need preparation too. Before listing someone, have a conversation about the specific role you're applying for. Share the job description and remind them of specific projects you worked on together.
If you built a revolutionary data deduplication system that saved the company millions, make sure your reference remembers the details and impact.
In our digital age, LinkedIn recommendations can serve as pre-references, especially for Data Engineers. A well-written recommendation from a respected professional in the data space can carry significant weight. Consider cultivating these throughout your career, not just when job hunting.
They provide social proof that's immediately accessible to recruiters and hiring managers.
What if your best data engineering work was at a company with strict confidentiality agreements? Or what if you're making your first transition into data engineering from a related field? In these cases, focus on references who can speak to transferable skills - your analytical thinking, problem-solving abilities, and capacity to learn new technologies quickly.
A reference confirming you mastered Apache Spark in three weeks for a critical project can be more powerful than years of experience with less challenging work.
If you're applying internationally, be mindful of time zones when listing references.
Nothing frustrates a hiring manager more than trying to reach a reference at 3 AM their time. Include the reference's location or time zone, and consider having at least one reference in a compatible time zone with your target job location.
Also, be aware that reference checking practices vary significantly between countries - what's standard in Silicon Valley might be unusual in Singapore.
Let's be honest - as a Data Engineer, you'd probably rather spend your time optimizing a particularly stubborn SQL query than writing a cover letter.
You might even be tempted to skip it entirely, thinking your technical skills speak for themselves. But here's the reality: while your resume shows you can build robust data pipelines, your cover letter shows you can communicate why those pipelines matter to the business. And in a role where you'll often bridge the gap between technical and non-technical teams, that communication ability is gold.
Unlike software developers who might get away with letting their GitHub do the talking, Data Engineers operate in a unique space.
You're not just writing code - you're architecting the very foundation that enables data-driven decisions across an entire organization. Your cover letter needs to convey that you understand this responsibility and can articulate technical concepts to diverse audiences.
Think of your cover letter like designing a data pipeline - it needs a clear flow from input to output. Start with the problem (why you're interested in this specific role), process it through your experience (how your skills align), and deliver valuable output (what you'll bring to the team).
Here's how to structure it effectively:
❌ Don't write generic, technical jargon-filled paragraphs:
Dear Hiring Manager,
I am applying for the Data Engineer position. I have experience with Python, SQL,
and AWS. I have built many ETL pipelines and worked with big data technologies.
I think I would be a good fit for your company.
✅ Do tell a compelling story that connects your experience to their needs:
Dear Data Engineering Team at TechCorp,
When I read that you're scaling from processing 10TB to 100TB of daily data, I immediately
thought of the similar challenge I tackled at CurrentCompany. By redesigning our data
pipeline architecture using Apache Spark and implementing intelligent partitioning strategies,
I reduced processing time by 70% while cutting infrastructure costs by $200K annually.
Your job posting mentions the need for real-time analytics capabilities. In my current role,
I architected a streaming solution using Kafka and Flink that processes 2 million events per
minute with sub-second latency, enabling our product team to make instant decisions based on
user behavior...
Here's what separates great Data Engineers from good ones - the ability to connect technical solutions to business outcomes. Your cover letter should demonstrate this skill. Don't just mention that you implemented a data warehouse; explain how it enabled marketing to increase campaign ROI by 40%.
Don't just say you know Spark; describe how you used it to reduce report generation time from hours to minutes.
Maybe you're transitioning from a software engineering role, or perhaps you're a recent graduate with more academic than industry experience. Your cover letter is the perfect place to address these situations proactively.
Explain how your software engineering background gives you a unique perspective on building maintainable data systems, or how your research project on distributed systems directly applies to modern data engineering challenges.
In the USA and Canada, cover letters are typically expected and should be concise - one page maximum. UK employers often prefer a more formal tone but similar length. Australian companies tend to appreciate a bit more personality while maintaining professionalism.
Regardless of region, avoid rehashing your resume; instead, use the cover letter to provide context and demonstrate cultural fit.
For Data Engineer positions, consider including a brief technical insight that shows your expertise. Maybe you noticed they use a specific technology stack and you can share a relevant optimization technique. Or perhaps you've solved a similar challenge they mention in their engineering blog.
This shows you've done your homework and can contribute from day one.
After diving deep into the art and science of crafting the perfect Data Engineer resume, let's distill everything into actionable takeaways you can implement immediately:
Ready to transform your data engineering experience into a resume that opens doors? Resumonk makes it easy to create a professional, impactful resume that captures your unique journey as a Data Engineer. Our AI-powered platform understands the nuances of technical roles and helps you articulate your achievements in ways that resonate with hiring managers. With beautifully designed templates optimized for readability and smart suggestions tailored to data engineering roles, you can focus on showcasing your expertise while we handle the formatting and structure.
Start building your standout Data Engineer resume today!
Join thousands of data professionals who've successfully landed their dream roles using Resumonk. Our intuitive platform guides you through each section, ensuring you don't miss any crucial details that could make the difference between a callback and silence.
Get started with Resumonk now and let your data engineering expertise shine through in every line.